12个最强大的音频AI模型

如果你认为大型语言模型是人工智能演化的顶峰,那就错了——2025年已经正式将音频AI 推上了突破之星。从能像你最好的朋友一样聊天的语音助手到可以从10秒片段中克隆摩根·弗里曼声音的模型——我们正进入一个机器不仅能理解文本,还能说话、倾听和唱歌的时代。

在这篇博客中,我们将深入探讨目前最令人兴奋的一些开源音频AI模型——这些模型不仅强大,而且实用且易于使用 。无论你是要构建一个语音机器人、用你自己的声音配音动画、转录会议,还是生成定制的音乐轨道——这里都有适合你的模型。
所以系好安全带,因为我们即将开始探索!
1、对话式AI
对话式AI涵盖了能够以自然、人性化方式与人交谈的系统。
这些模型驱动着诸如语音助手和聊天机器人之类的东西,它们可以理解你的言语并用语音回答。日常生活中,当你问Siri或Google Home一个问题并得到口头回答时,这就是对话式AI——目标是让这些互动感觉友好且人性化。

1.1 Dia-1.6B
Dia-1.6B 是一种新的专注于对话的开源TTS(文本到语音)模型。想象一下,给它一段人们交谈的剧本:它会为每个角色生成逼真的声音,包括情绪和非语言声音(如笑声或叹息)。
Dia可以将书面对话转换为逼真的会话语音,包括使声音听起来自然的停顿和语调变化。它经过上下文训练,因此听起来像是真正的来回对话,而不是单调的公告。1.2 Sesame-CSM-1B
Sesame-CSM-1B 来自Sesame AI团队(由一位Oculus VR联合创始人共同创立),代表“对话语音模型”。这个模型也可以从文本(甚至音频提示)生成语音。简单来说,你可以给它文本,它会以自然的方式朗读出来。它的独特之处在于它使用了基于Llama的神经网络来考虑对话的流畅性。它甚至可以接受一点示例音频(比如语音风格)并继续以那种风格说话。它不能表达笑声、悲伤等情感,就像Dia一样。
2、语音克隆
语音克隆AI让你只需一小段音频剪辑就能复制或模仿一个人的声音。
想象一下,AI取一小段你的讲话样本并“学习”它,这样它可以用你的声音朗读任何文本。

这在娱乐和实际应用中都很重要:创作者可以在游戏中或动画中加入自己的声音,人们可以用选定的声音制作有声书,或者某人可以拥有一个听起来完全像他们的个性化助手。
2.1 F5-TTS
F5-TTS 是一种前沿的开源语音克隆模型。它的创造者称其为零样本语音克隆系统,意思是你只需要10秒钟的语音样本就可以立即模仿该声音,而无需额外的训练
实际上,这意味着F5-TTS可以高质量且快速地克隆几乎任何声音。评论者指出,它可以从短片段中生成几乎逼真的音频,并且设计为即使在普通的硬件上也能快速运行。2.2 Fish-TTS (Fish Speech)
Fish Speech(有时称为Fish-TTS)是另一个开源的语音克隆系统,以其多功能性而闻名。与F5类似,它可以接受一段短样本(例如10-30秒)并生成该声音的语音。它还支持多种语言。一个突出的特点是它不依赖传统的音素,因此可以处理任何脚本(拉丁字母、日语、阿拉伯语等)的文本,而无需特殊的发音指南。这意味着你可以给Fish Speech提供多语言文本,并听到同一个克隆声音自然地朗读出来。开源贡献者称赞它速度快且支持多语言。想象一下用你自己的声音为故事配音成日语或法语——Fish Speech使得这种跨语言语音克隆成为可能。
2.3 Zonos (Zyphra Zonos)
Zonos 是Zyphra的新TTS模型,也在语音克隆方面表现出色。它经过了超过200,000小时的语音数据训练,可以产生非常富有表现力且高质量的声音。它甚至允许调整克隆语音的速度和情感(比如让它听起来开心或悲伤)。3、基础TTS
基础TTS(文本到语音)模型只是将书面文本转换为口语。

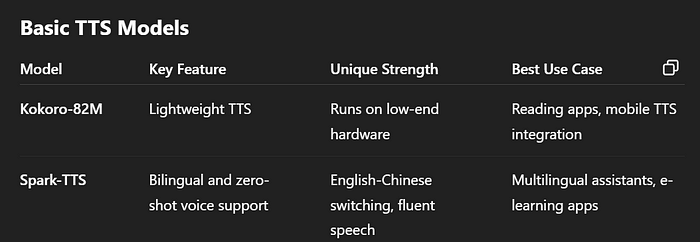
3.1 Kokoro-82M
Kokoro-82M 是一种轻量级但功能强大的开源TTS引擎。它只有8200万个参数(相对较小),但仍能提供与更大模型相当的语音质量。换句话说,Kokoro可以在普通硬件(甚至笔记本电脑或智能手机)上高效运行,并生成非常自然的语音。其开放许可和小巧的规模意味着开发人员可以在应用程序中使用它,而不会产生高昂的成本或需要大型服务器。你可以想象Kokoro在一个基本设备上大声朗读睡前故事——它被设计为快速且资源友好,同时仍然听起来很好。
3.2 Spark-TTS
Spark-TTS 是一种较新的高级TTS模型,利用大语言模型实现更流畅的语音。它旨在实现高准确度和自然的声音。Spark-TTS甚至可以以零样本方式克隆声音,并无缝处理双语文本(英语和中文)。实际上,这意味着Spark-TTS可以读取混合语言句子并在切换声音时保持自然。例如,如果你给它一个英文句子然后是一个中文句子,它会自然地发音,并且可以使用特定的声音样本来模仿某个特定说话者的语音。4、音乐生成
音乐生成模型根据输入(通常是文本描述)创建新的歌曲或声音。
你可以将其视为给计算机一个提示,比如“一首带有萨克斯风的快乐爵士曲”,然后它会根据这个想法创作出一首原创音乐。

这对音乐家和创作者来说很令人兴奋,因为他们想要即时的背景音乐或灵感。在日常生活中,人们正在使用这些工具快速制作视频的配乐、玩新的歌曲创意,甚至生成游戏音效。
4.1 Meta MusicGen
MusicGen 是Meta AI的开源音乐生成器。它可以接受文本描述并生成符合该描述的音乐片段。例如,如果你告诉它“柔和的钢琴旋律伴随着轻柔的雨声”,它会创作出符合这个想法的曲目。MusicGen是在授权音乐上训练的,并且有不同的大小版本来平衡质量和速度。
在实际应用中,你会用它来快速获得歌曲创意或背景循环。一个业余创作者可能会在Hugging Face上使用MusicGen为他们的视频游戏起草一首曲子,或者只是尝试不同的音乐风格组合。4.2 ACE-Step
ACE-Step 是一个全新的开源“基础”音乐模型。其名称代表“迈向音乐生成的一步”。ACE-Step 的显著特点是极快且连贯:它可以在高端GPU上大约20秒内生成完整的4分钟歌曲,比许多旧的AI音乐系统快15倍 。尽管速度快,但它旨在保持音乐结构,使旋律、节奏和和声一起有意义。换句话说,ACE-Step试图融合现代音乐的丰富性(包括歌词、乐器、长段落等)和快速生成的需求。你可以用ACE-Step创建或重新混音完整的歌曲。例如,艺术家可以写一些歌词,加上样式提示输入ACE-Step,然后得到一个包含人声的完整曲目。其开放架构甚至允许微调以完成特殊任务,比如只生成乐器部分或适应样式。5、自动语音识别(ASR)
ASR模型听语音并将其转换为文本。这项技术驱动着语音输入、会议转录和语音激活搜索等功能。
你随处可见ASR:当你对语音助手说话并将其文字化时,或者当YouTube自动为视频添加字幕时。
它在日常生活中很重要,因为它使语音内容可搜索并可用作文本,有助于从智能家居控制到无障碍(如实时字幕)等各种任务。简而言之,ASR将音频波转换为单词,以便计算机理解和响应语音。

5.1 OpenAI Whisper
Whisper 是OpenAI的知名ASR模型。它在680,000小时的多语言音频上进行了训练,因此非常稳健,能够应对不同的口音、噪声,甚至是非英语语言。OpenAI指出,Whisper在英语语音上的准确性接近人类水平,甚至可以将语音翻译成英语。实际上,Whisper可以可靠地转录音频。因为它是完全开源的,开发者可以在自己的计算机或服务器上运行Whisper,以构建自定义的语音输入功能。5.2 NVIDIA Parakeet-v2
Parakeet-v2 是Nvidia的最新开源ASR系统。它旨在极其快速和准确——据报道,在强大的GPU上,它可以每秒转录一小时的音频 。它还在开放ASR排行榜上以约6%的词错误率领先,甚至超过了Whisper和其他顶级模型。除了原始速度外,Parakeet-v2还具有内置标点符号、大写字母以及支持转录歌词等实用功能。因为其发布在宽松许可下,任何开发者都可以自由使用。想象一下将Parakeet-v2添加到播客应用中,这样你在录制时就可以立即创建可搜索的转录记录——它的速度和质量使先进的语音转文字工具更加普及。
6、音频到音频模型
音频到音频模型可以输入音频提示并输出音频作为响应
一个会说话的语言模型
6.1 Kimi-Audio
Kimi-Audio 是一个非常通用的开源音频基础模型。它被设计为在一个包中处理各种各样的音频任务。例如,Kimi-Audio可以进行语音识别(像ASR一样)、音频问答、情感识别,甚至支持“语音对话”,这意味着你可以真正与它聊天,它将以语音形式回应。
其关键技巧之一是将音频和文本结合起来:它可以摄取原始音频,将其分解为令牌,并通过一个处理语言的大变压器神经网络运行这些令牌。结果是一种理解音频上下文并能生成音频的人工智能。实际上,你可以使用Kimi构建一个交互式语音助手,它不仅能听懂和转录你的话,还能以口头形式进行对话。因为其是开源的,研究人员对使用Kimi-Audio进行各种新音频应用的实验感到兴奋。7、结束语
就这样——2025年(字面和比喻上)最强大、开源的音频AI模型 脱颖而出。无论你是想构建会说话的助手 、制作超现实的配音 、生成按需音乐 ,还是为你的应用程序添加实时转录 功能——都有一个适合你需求的AI模型——很可能就在GitHub仓库里。
真正的关键是:这些模型不仅仅是酷炫的技术演示——它们是经过实战检验、高度可用且开放给每个人 的。我们不再局限于通过文本与AI互动——我们正在进入一个机器说话、倾听、唱歌,甚至表达情感的时代。
所以,如果你是一名开发人员、研究人员、创作者,或者仅仅是对音频技术感兴趣的人——现在是时候进行实验了。选择一个模型,克隆你的声音,重新混音一首曲子,构建你的AI助手。因为人类与计算机交互的未来? 不仅仅是文本了——它是一场对话。
原文链接:12个最强大的音频AI模型 - 汇智网
《2024最接地气盘点!国内这九大AI模型到底有多能耐?》
最近跟朋友聊AI发现个怪事——明明咱国产大模型早就不比ChatGPT差,可好多人连这些"数字大脑"叫啥名都不知道!今天咱们就唠唠这些藏在科技公司背后的"智能小能手",保准让你选AI像点菜一样明白!
第一位:豆包(字节跳动)
这哥们儿就像你们班那个随叫随到的学霸,写作文能拿满分,算数学题也不含糊。最绝的是跟它语音唠嗑,活脱脱像有个24小时在线的知心朋友。不过碰到特别冷门的前沿科技问题,它可能就得抓瞎——毕竟人家主攻的还是咱老百姓的日常需求。

第二位:文心一言(百度)
要说玩文字游戏,这位绝对是行家!写出来的散文能让语文老师拍案叫绝,编广告词更是分分钟的事。但要是问它量子物理之类的高深问题,保不齐就给你背百度百科——人家强项毕竟是中文创作嘛!

第三位:讯飞星火(科大讯飞)
这绝对是个"声控福利"!跟它说话就像跟新闻主播聊天,吐字清晰得能去考普通话。不过让它写篇小作文可能就露怯了,典型"偏科生"说的就是它。

第四位:通义千问(阿里云)
活脱脱的"全能型选手",聊天、创作、翻译样样都能来点。但要论深度逻辑推理,就跟让马拉松选手跑百米似的——不是说不行,就是没那么出彩。

第五位:Kimi(月之暗面)
处理长篇大论的神器!200万字的小说它读起来跟玩儿似的,简直就是文字工作者的"人形外挂"。不过你要是想让它处理图片视频,那还是趁早换人吧。

第六位:智谱清言(智谱AI)
学术圈的真爱!写论文搞创作绝对是把好手,但要让它即时回答冷知识,可能就得现查资料了——典型的"专家型人才"。

第七位:腾讯元宝
这活脱就是个"数字瑞士军刀",查资料、做总结、剪视频样样都沾边。日常使用绝对够用,但碰上特别专业的难题,可能就得找外援了。

第八位:秘塔(秘塔科技)
法律金融圈的老司机!处理专业文件那叫一个利索,不过普通用户用起来可能觉得不够"贴心"——毕竟人家走的是专业路线。

第九位:天工AI(昆仑万维)
新晋的潜力股!跟ChatGPT掰手腕都不虚,不过毕竟资历尚浅,偶尔也会犯点"新人错误"。但假以时日绝对是个狠角色!

这些AI大模型就像九个身怀绝技的武林高手,有的擅长舞文弄墨,有的精通语音绝活。关键看你想解决什么问题——找对象还得看合不合适呢,选AI不也是这个理儿?
相关问答
有哪些受欢迎的AI图像生成模型?-ZOL问答
翻译机百度百度AI翻译机讨论回答(4)稳稳的diffusion系列特别火尤其是stablediffusion超多人都在用还有像dall·e和midjourney也都挺受欢迎的很多艺术家都...
工业ai大模型有哪些?
工业AI大模型是指用于工业领域的深度学习模型,通常用于处理大规模数据集并提供准确的预测和决策支持。以下是一些常见的工业AI大模型:Transformer模型:Transfo...
常见ai模型和优缺点?
一般来说,常见的AI模型包括神经网络(NeuralNetwork)、支持向量机(SupportVectorMachine)、决策树(DecisionTree)等。它们各有优缺点:神经网络精度高...
ai模型是什么意思-业百科
ai模型是什么意思,AI模型是指基于已有的数据集运行深度学习算法所得到的输出,可简单理解为计算机在大量数据中学到的技能,这项技能本身也是一种算法。AI智能拥有...
国内的ai模型哪个最好?
根据IT市场研究和咨询公司国际数据公司(IDC)最新发布的《AI大模型技术能力评估报告2023》显示,目前在中国主流的大模型中,百度推出的文心大模型3.5处在相对领...
ai人工智能大模型包括格林深瞳吗?
是的,人工智能大模型包括格林深瞳。格林深瞳是由OpenAI开发的一种强大的自然语言处理模型,它具有极高的语义理解和生成能力。它被广泛应用于机器翻译、文本生...
什么是ai模型通俗易懂的解释?
AI模型是人工智能(AI)系统中的一个核心组件,它可以被看作是一种计算机程序或数学算法,用于对数据进行处理和学习,从而能够执行特定的任务。为了更好地理解AI...
ai大模型有几种用法?
大模型有多种用法。首先,它们可以用于自然语言处理任务,如机器翻译、文本生成和情感分析。其次,它们可以用于计算机视觉任务,如图像分类、目标检测和图像生...
训练ai模型电脑配置?
在配置用于训练AI模型的电脑时,需要考虑以下几个关键部件:1.处理器:建议选择具有高性能的多核心CPU,例如IntelCorei9或AMDRyzenThreadripper等。这是因...
ai大模型是什么?
1AI大模型是一种结合了大数据、大算力和强算法的产物,它包含了“预训练”和“大模型”两层含义。预训练是指在大规模数据集上完成训练,学习出一些特征和规则;...

